
[實戰解析] 從 SQL Server 到 PostgreSQL:連線數耗盡危機與自動化備份解法
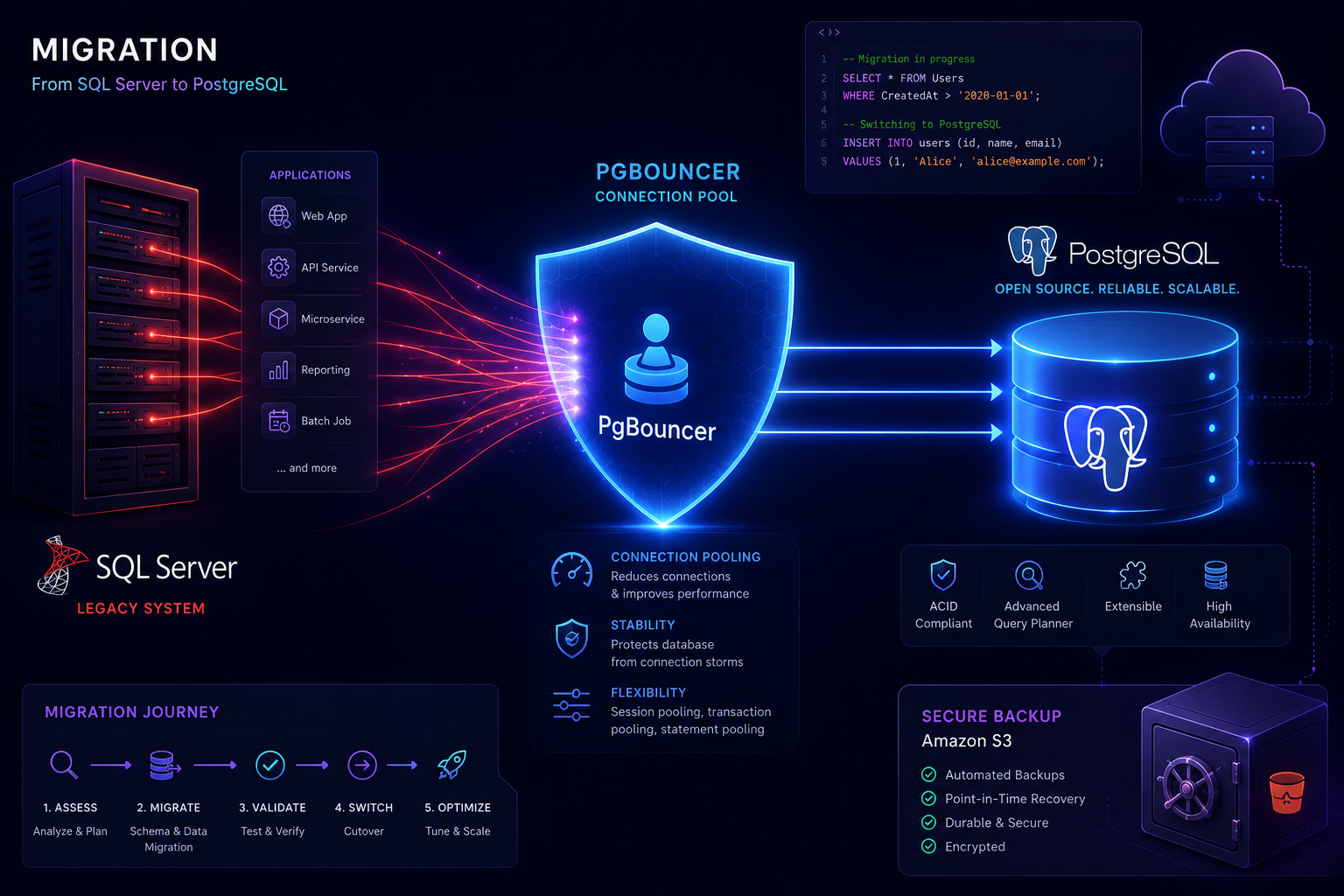
之前執行了一個系統重構的案子,主要的任務是將原本的資料庫從 SQL Server 全面搬遷到開源的 PostgreSQL。原本以為大換血的過程已經平安落幕,沒想到轉換資料庫穩定運行一段時間後,系統卻無預警發生應用程式連不上資料庫的狀況!當下只能先緊急重啟資料庫恢復服務,但這治標不治本。這篇文章就來分享,我如何追查出連線數耗盡的真兇,並透過在 CapRover 部署 PgBouncer 徹底解決問題,最後分享一套我自寫的 PostgreSQL 自動備份到 S3 的實用工具。
1. 遭遇痛點:資料庫連線數耗盡危機
連不上資料庫的驚魂夜
系統轉移到 PostgreSQL 並部署在 CapRover 上穩定運行了一段時間後,客服突然回報系統發生異常。我一查 API 的 Log,赫然發現滿滿的都是 SqlSugar.SqlSugarException,具體錯誤訊息寫著:
The connection pool has been exhausted, either raise MaxPoolSize (currently 100) or Timeout (currently 15 seconds)
DbType=PostgreSQL
說白了,就是應用程式端的連線池已經被徹底耗盡,無法再建立新的資料庫連線。當下為了盡快讓服務恢復,只能先摸摸鼻子把應用程式與 PostgreSQL 容器重啟,系統才暫時恢復正常。
追查真兇:Connection Count 爆表
重啟只能救急,如果不找出根本原因,半夜一定還會被叫起來修機器。我回頭仔細檢查當時的連線狀態,發現系統在某些高併發的情境下,會瞬間開啟大量的連線。雖然我們後端使用了 SqlSugar 作為 ORM,但可能因為舊有的架構設計,或是未妥善控管非同步操作,導致這些連線沒有被及時回收。
SQL Server 與 PostgreSQL 的連線機制差異是導致這次危機的核心原因。兩者在底層架構上有著根本的不同:
- SQL Server(Thread 模式):採用多執行緒(Multi-threaded)架構。當有新連線時,只需配置一個輕量級的 Thread 即可處理。因此,SQL Server 預設就能輕鬆支撐數千個同時連線,這讓開發者往往習慣在應用程式端設定龐大的 Connection Pool 而不自覺。
- PostgreSQL(Process 模式):採用多行程(Multi-process)架構。每建立一個新連線,PostgreSQL 都必須在作業系統層級
fork出一個完整的獨立 Process(Backend Process)來服務。這樣的設計提供了絕佳的穩定性與隔離性,但代價是建立與維持連線的記憶體和 CPU 開銷極高。因此,PostgreSQL 預設的max_connections為了保護主機,通常只設在 100 左右。
當習慣了 SQL Server 寬鬆連線數的應用程式直接搬移過來後,其內建的連線池(如 SqlSugar 預設的 MaxPoolSize: 100)在面臨瞬間高併發時,會試圖開啟大量實體連線。這會立刻耗盡 PostgreSQL 的 max_connections,導致後續所有請求都被無情拒絕。
2. 決策與實作:導入 PgBouncer 建立連線池
要解決這個問題,有幾個方向:
- 調高 max_connections:治標不治本,而且會大幅增加機器的記憶體開銷,萬一連線數真的無上限增長,最後就是整台機器 OOM (Out of Memory) 掛掉。
- 改寫應用程式的連線池:這是最根本的解法,但礙於時程壓力,且舊系統的程式碼如義大利麵般盤根錯節,短期內下足重本去改寫風險太高。
- 導入中介層做連線池 (Connection Pooling):這是我最終選擇的優雅解法。
為什麼需要 PgBouncer?
PgBouncer 是一個輕量級的 PostgreSQL 連線池代理伺服器。它的概念很簡單:擋在應用程式與 PostgreSQL 之間。應用程式以為自己連上了幾百個資料庫連線,但實際上 PgBouncer 在背後只維持了幾十個真實的 PostgreSQL 連線,並在不同的請求之間快速切換重複使用。這樣一來,既能滿足應用程式瞬間高併發的需求,又能保護後端資料庫不被連線洪流沖垮。
系統架構規劃:舊架構 vs 新架構
這次的環境架設在 CapRover 上,我們決定將 PgBouncer 包裝成一個獨立容器,與 PostgreSQL 部署在同一個內部網路。以下是導入 PgBouncer 前後的架構對比:
【舊架構】容易引發災難的直連模式
graph LR
App1[應用程式 Request 1] -->|耗費資源建立 Process| DB[(PostgreSQL)]
App2[應用程式 Request 2] -->|耗費資源建立 Process| DB
App3[應用程式 Request N] -->|瞬間打滿 max_connections| DB
style DB fill:#ffcccb,stroke:#ff0000,stroke-width:2px
【新架構】導入 PgBouncer 的連線池模式
graph LR
App[應用程式] -->|大量且頻繁的連線請求| PgBouncer[PgBouncer 連線池代理]
PgBouncer -->|重複利用少量穩定的實體連線| PostgreSQL[(PostgreSQL)]
style PgBouncer fill:#f9f,stroke:#333,stroke-width:2px
style PostgreSQL fill:#ccffcc,stroke:#009900,stroke-width:2px
在 CapRover 的實作上非常簡單,直接建立一個新的 App 跑 PgBouncer 的 Docker image,並透過環境變數設定好後端的 PostgreSQL 連線資訊,最後把應用程式的連線字串改成指向 PgBouncer 即可。導入之後,資料庫的連線數從原本會飆破百,穩定維持在 20 上下,系統再也沒發生過斷線危機。
3. 進階痛點:PostgreSQL 的自動備份挑戰
解決了連線數問題,另一個棘手的任務浮出水面:資料庫備份。
以前在 Windows Server 上,SQL Server 的備份排程可以用內建的 Agent 或是寫個簡單的 PowerShell 腳本搞定。但現在轉移到了 CapRover 上的 Docker 環境,雖然官方有一些備份外掛,但我希望能有一套更純粹、更容易設定,而且能自動把備份檔拋到 AWS S3 存放的解決方案。
尋找備份方案的權衡
我評估過幾種做法:
- 在 PostgreSQL 容器內寫 CronJob:這破壞了容器的單一職責原則,且如果容器升級,設定很容易不見。
- 使用現成的第三方 Docker 備份工具:找了幾個開源專案,要嘛設定太複雜,要嘛不支援 S3 上傳,總覺得不太順手。
4. 具體實作:客製化 CapRover 定時備份程式
既然找不到順手的,那就自己幹一個吧!我開發了一個專門為 CapRover 環境設計的 Python 備份服務,並開源在 GitHub 上:
🔗 https://github.com/markx2008/caprover-db-backup
核心架構與設計特點
這套工具的設計重點在於「極簡部署」與「高相容性」,可以直接在 CapRover 建立一個 Worker App 部署。它的幾個核心亮點包括:
- 內建排程與客戶端:容器內置 Python APScheduler(完全不需依賴 Linux cron daemon)與 PostgreSQL Client 18,啟動後就會默默在背景依排程運作。
- 支援多資料庫與 S3 相容:透過一份 JSON 設定,可以一次備份多個不同主機上的資料庫,並且上傳到任何相容 S3 的儲存服務(如 AWS S3、MinIO 或 Cloudflare R2)。
- 輕量暫存機制:備份時會自動執行
pg_dump -Fc將.dump檔暫存在容器的/tmp目錄,確定上傳成功後會自動刪除清理,完全不需要綁定持久化 Volume (Persistent Volume)。
極簡設定:全環境變數驅動
你完全不需要改 code,只要直接使用官方的 Docker Image ghcr.io/markx2008/caprover-db-backup:latest,並在 CapRover 介面上填好環境變數(ENV)即可:
- 排程與時區設定:例如
BACKUP_CRON=0 3 * * *(每天半夜三點執行)、TZ=Asia/Taipei。 - S3 儲存設定:包含
S3_ENDPOINT、S3_BUCKET、S3_ACCESS_KEY、S3_SECRET_KEY等。 - 多資料庫連線清單(
DATABASES_JSON):將要備份的資料庫以 JSON Array 格式填入,例如:1
2
3
4
5
6
7
8
9
10[
{
"name": "app1",
"host": "postgres-1.example.local",
"port": 5432,
"database": "app1_db",
"username": "postgres",
"password": "change-me"
}
]
設定完成後,系統就會依照排程自動執行備份,並依照 s3://{S3_BUCKET}/{S3_PREFIX}/{db_name}/{yyyymmdd}/{db_name}-{timestamp}.dump 的整齊路徑拋上 S3,實踐異地備援的原則。萬一需要還原,只要下載 .dump 檔並使用 pg_restore 即可輕鬆恢復資料。
5. 總結收穫
從 SQL Server 搬遷到 PostgreSQL,雖然省下了可觀的授權費,但也代表我們必須自己掌握更多底層的維運細節。
透過這兩個實戰經驗,我們可以歸納出幾個重點:
- 架構保護機制:永遠不要讓應用程式直接「裸奔」連線到核心資料庫。在中間夾一層 PgBouncer 作為緩衝,能大幅提高系統的容錯力。
- 備份自動化與異地備援:資料庫再穩,也敵不過機房失火或是手殘誤刪。透過容器化的自動備份工具並上傳至 S3,是保障心血的最後防線。
以上就是這次從 SQL Server 搬遷到 PostgreSQL 的實戰經驗分享,希望能對大家有所幫助!



![[實戰解析] BSC GameFi 練習專案:如何利用 Next.js + Node.js 監聽器打造可驗證公平的 Web3 混合帳本](/images/795cb17f-50cb-4bdb-8abf-1c2445db2b98.png)
![[實戰解析] 匯率展示系統:從零到一的 MVP 最小可行性架構規劃](/images/exchange-board-mockup.svg)

